
Apache Kafka has, over the past few years, become the go-to platform for building scalable, and fault-tolerant data pipelines and event-driven applications.
Unlike other messaging systems, which are easier to install and quickly get up and running, Kafka has a little bit steeper learning curve when it comes to installation, access management and overall configuration.
This article aims to show how to deploy a distributed Kafka cluster in Kubernetes, using Strimzi, in a secure (SSL) and reliable (distributed and self-healing) way and with user access declarative governance.
It will not go deep into what Kafka is and how it works internally, despite touching a few core concepts which are relevant for better understanding how Strimzi works and the topology of this deployment.
Kafka Cluster topology using zookeeper
Up to until recently, Kafka wasn’t able to function by itself, needing zookeeper to function, even as a single node cluster. As you might have understood, zookeeper is no longer required to run a Kafka cluster, but it is still the most common deployment model for Apache Kafka clusters.
Kafka brokers make up the heart and muscles of the Kafka cluster. These are the servers responsible for managing and storing data streams. Each Kafka broker has a unique ID and it can work together with the other brokers to create a distributed cluster. It’s possible to create single-node clusters, although this represents a risk in terms of availability and durability.
Kafka Brokers are responsible for:
- Dealing with Data Storage: Brokers store topic data on disk. Each topic is divided into partitions, and these partitions are spread across brokers for balanced storage. The number of partitions in a topic can be defined during the creation of the topic
- Performing Data Replication: Brokers can replicate partitions across other brokers to ensure fault tolerance. If one broker goes down, replicas on other brokers ensure no data is lost. The number of copies (replicas) of a partition are defined when creating a topic and can also be defined as a default in a cluster.
- Handling Client Requests: Producers send messages to brokers, while consumers fetch data from brokers. The brokers handle these read and write operations efficiently.
- Handling Load Balancing: By distributing partitions across brokers, Kafka makes sure the workload is balanced across the cluster.
While the brokers perform the heavy lift work, they need to be coordinated, and that’s where zookeeper comes into play. Zookeeper is the brain of the cluster, ensuring nodes are coordinated and each node is doing “their part”.
Its main responsibilities are:
- Performing Leader Election: Zookeeper helps elect a controller broker, which manages partition leadership within the cluster, and fails over to another broker if the leader node fails.
- Managing Metadata : It stores metadata about topics, partitions, and broker configurations. This especially useful as with topic data consumption, as consumer groups need their consumer offset (the position they have previously consumed data to) to be remembered by the cluster.
- Tracking the Cluster State : Zookeeper tracks the status of all brokers, ensuring smooth operation and needed leader elections.
- Validating Access Control: It supports authentication and authorization for Kafka clients (which are discussed in more detail below)
The cluster we’ll setup later in this article has 3 Zookeeper instances and 3 Broker nodes.
Kafka kraft vs zookeeper
As seen in the previous section, Apache Kafka’s architecture traditionally relies on Zookeeper for cluster management. Recently, a new mode called Kafka Raft (KRaft) can replace Zookeeper and consolidates cluster management into Kafka itself without the need for Zookeeper. Both approaches have some advantages and drawbacks, which we’ll explore briefly.
Zookeeper has been on the market for a long time now, and
- Proven value: Zookeeper has been used widely across distributed systems, providing reliability and stability, making it easy to find resources and community support.
- Isolation: As a separate system, Zookeeper isolates cluster coordination, reducing complexity within Kafka itself and ensuring brokers only have to deal with what they traditionally dealt with.
- Fault Tolerance: Zookeeper ensembles are resilient to failures, ensuring Kafka’s operations remain uninterrupted as long as a majority of nodes are operational (all configurable).
- Tooling Ecosystem: A rich ecosystem of tools exists for monitoring, managing, and troubleshooting Zookeeper, including metric collectors and pre-defined dashboards.
KRaft is Kafka’s more recent internal consensus protocol, introduced in Kafka 2.8 it is able to replace Zookeeper. It uses the Raft consensus algorithm for metadata management and fault tolerance. It works by integrating metadata directly into the brokers and crates a KRaft controller quorum for storage, replication and leader election.
Despite being more recent, when compared to Zookeeper, it presents a few advantages:
- Simpler Architecture: No need for a separate Zookeeper cluster; Kafka is able to managed its metadata natively and internally. This helps reducing operational and deployment overheads.
- Better Scalability: KRaft is built for modern Kafka workloads and scales more effectively than Zookeeper-based Kafka, removing the Zookeeper bottleneck, especially for large clusters.
- Performance Improvements: By not relying in Zookeeper, KRaft reduces latency in metadata operations.
- Easier Maintenance: Simplifies deployment, upgrades and maintenance operations by removing the need to coordinate changes between Kafka and Zookeeper.
With this in mind, and knowing Strimzi supports KRaft, we’ll still use Zookeeper for this example.
Kafka authentication and authorization
Kafka has a few different authentication modes
- SSL – Kafka uses TLS/SSL certificates to authenticate clients and brokers. Each client (and broker) presents a certificate during the handshake. It requires setting up a Certificate Authority and configuring Kafka with a trusted Keystore. Strimzi automates big part of this and we’ll use SSL authentication in this example.
- SASL/PLAIN – SASL stands for Simple Authentication and security Layer. Clients use plaintext username and passwords which are stored in configuration files. It’s lightweight but not very secure and should only be used for internal clusters that don’t require strong security.
- SASL/SCRAM – SCRAM stands for Salted Challenge REsponse Authentication Mechanism. It’s similar to the PLAIN method, but usernames and passwords are stored in hashed formats using SCRAM-SHA-256 or SCRAM-SHA-512 algorithms.
- SASL/GSSAPI – Uses Kerberos for external authentication and Kafka does not store credentials.
- SASL/OAUTH – Uses an external identity provider capable of issuing Oauth2.0 bearer tokens which the clients present to the cluster.
- Delegation Tokens – Tokens issued by the Kafka broker allow short-term client access. This especially useful for workloads that require temporary access.
Regardless of the authentication mode, Kakfa mostly uses Role-Based Access Control using Access Control Lists (RBAC ACL) for authorization
ACLS specify which permissions client principals have on Topics, Consumer Groups and Cluster management.
Strimzi architecture
Strimzi is a Cloud Native Foundation (CNCF) incubating level Kubernetes operator for Kafka (https://www.cncf.io/projects/strimzi).
It aims to provide a way to run Apache Kafka in Kubernetes in a declarative way (allowing a Git-ops approach).
The operator is divided in 3 levels: The cluster operator, which monitors deployed clusters and ensures the desired cluster topology and state is created. This Operator is responsible for instantiating 2 cluster-level entity operators: topic and user. These entity operators will be responsible for transforming the declarative topic and user (including user ACL) into actual Kafka topics and Kafka users.
The user operator will also generate certificates for each user and store them as Opaque Secrets in Keycloak.
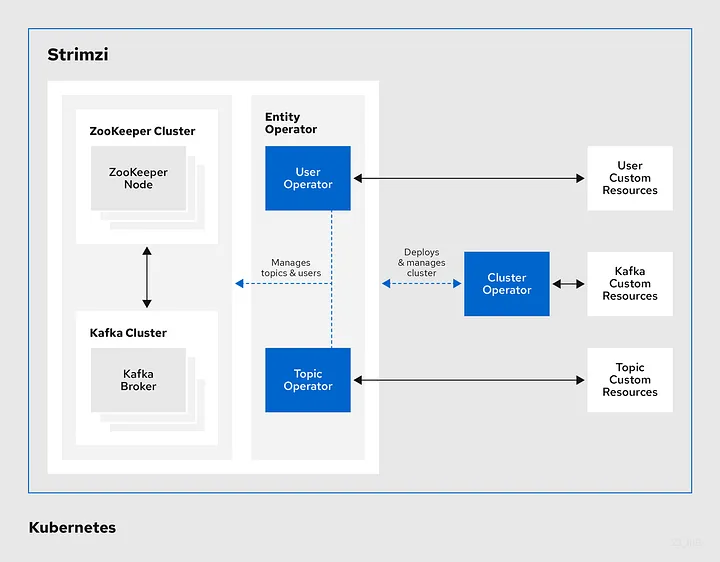
There is a lot to say about Strimzi, but that is not the purpose of this article. The official documentation shall provide more detailed information.
Installing the Strimzi Operator
Note: for this installation we’ll be using MicroK8s running locally in a single node Kubernetes cluster. MetalLB and Hostpath Storage are enabled.
Installing the Strimzi Operator can range from a quick and easy operation, to a slighly more complex approach, where defaults (such as namespaces) need to be modified.
We’ll use the simple approach and from the Downloads Page, we’ll copy the URL of the latest version of the Strimzi-cluster-operator yaml file. At the moment of writing this article, it’s version 0.44.0.
We’ll use the kafka namespace, so it’s a good idea to create it first:
kubectl create namespace kafka
Then we’ll install the operator using the following command
kubectl apply -f https://github.com/strimzi/strimzi-kafka-operator/releases/download/0.44.0/strimzi-cluster-operator-0.44.0.yaml -n kafkaA set of artefacts, including CRDs, Role-bindings, cluster roles and a deployment will be created:
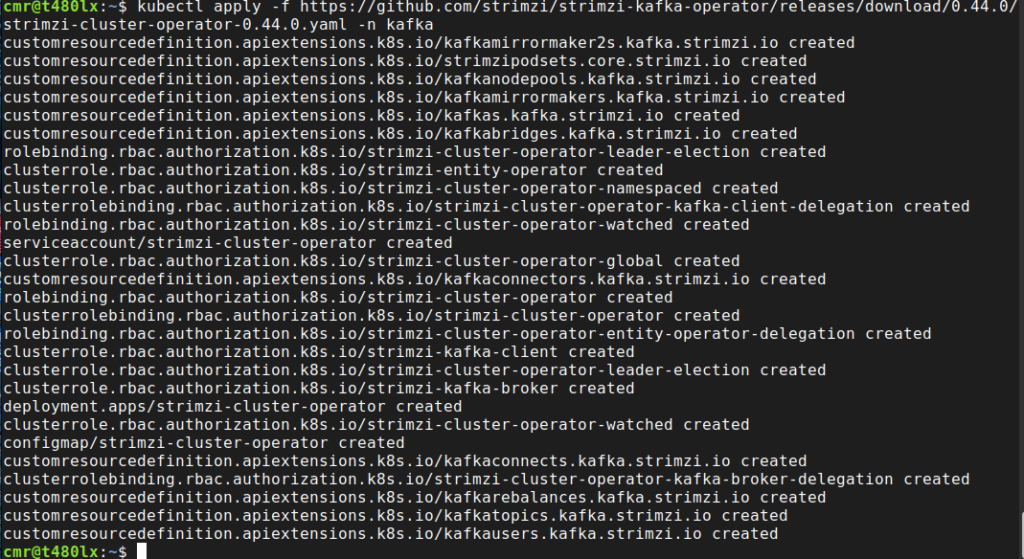
You can validate the operator is running by checking if the operator pod is running in the kafka namespace:
kubectl get pods -n kafka
Deploying a Kafka cluster with Strimzi
Alright, with the operator up and running, it’s time to create our cluster.
As previously mentioned, our test cluster will have 3 zookeepers and 3 brokers. We’ll also expose the 3 brokers to outside of the cluster, by creating a load balancer with an external IP for each of them (make sure metallb is enabled if you’re using microK8s, otherwise those external IPs will be pending forever).
The following YAML file contains the entire cluster specification:
apiVersion: kafka.strimzi.io/v1beta2
kind: Kafka
metadata:
name: devlab-cluster
spec:
kafka:
version: 3.8.0
replicas: 3
listeners:
- name: plain
port: 9092
type: cluster-ip
tls: false
- name: tls
port: 9093
type: loadbalancer
tls: true
authorization:
type: simple
config:
offsets.topic.replication.factor: 2
transaction.state.log.replication.factor: 2
transaction.state.log.min.isr: 1
default.replication.factor: 2
min.insync.replicas: 2
inter.broker.protocol.version: "3.8"
storage:
type: jbod
volumes:
- id: 0
type: persistent-claim
size: 2Gi
deleteClaim: false
zookeeper:
replicas: 3
storage:
type: persistent-claim
size: 2Gi
deleteClaim: false
entityOperator:
topicOperator: {}
userOperator: {}Before applying this file, let’s dissect it:
The first thing to notice is that there are 3 sections under spec:
- kafka – responsible for creating the brokers
- zookeper – responsible for creating the zookeeper nodes
- entityOperator – responsible for deploying the topic and user operator
As for the Kafka deployment, there a few key sections worth mentioning:
- the replica count, specifying how many brokers our cluster will have
- the listener collection, here specifying a plain text internal (cluster-ip) based listener on port 9092 and an external facing (load balancer) tls listener on port 9093
- Simple (ACL-bsaed) authorization
- basic cluster configuration (here specifying a few replication settings)
- storage – in this case claiming a meager 2GB persistent claim for each broker
Let’s now create the cluster by applying the file into the kafka namespace:
kubectl apply -f cluster-deployment.yaml -n kafka
A short message shall confirm the creation of the cluster, but still there are lots of things that can go wrong.
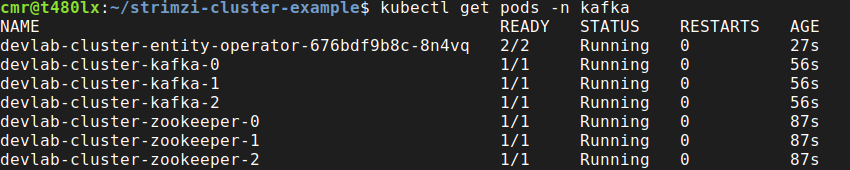
To fully validate the cluster creation, start by checking the pods in the kafka namespace. Give it some time, as it may take a while to first create everything:
kubectl get pods -n kafkaYou should see 7 new pods appearing (making it a total of 8 pods in the kafka namespace, considering the cluster operator one we saw earlier):
- 3 broker pods (lab-cluster 1, 2 and 3)
- 3 zookeeper pods (1,2,3)
- 1 entity operator pod with 2 containers inside (user and topic operator)
Make sure they all eventually transition to fully ready:
Next, we can see if the services for external and internal access to the cluster have been created:
kubectl get svc -n kafka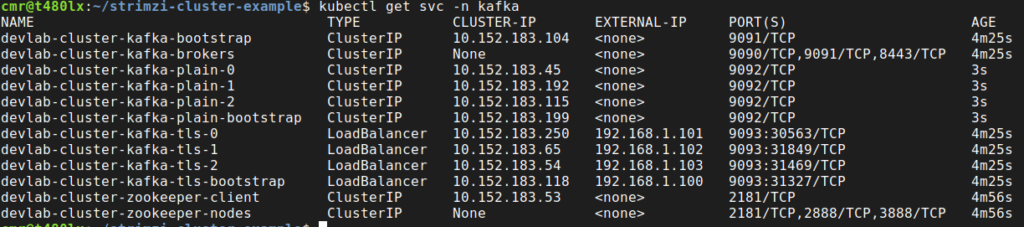
Notice the services for the TLS listener, for each broker have been created and do have an external IP address, which allows them to be targeted from outside K8s. Keep in mind this may not be suitable for certain workloads or environments.
There is one last thing to check: if the Kafka cluster is ready. To do this we can get and describe the special object type (created earlier by Strimzi): “Kafka”.
kubectl get Kafka -n kafka
As it’s possible to see, we see the cluster is in a Ready state, with 0 warnings and shows 3 brokers and 3 zookeeper nodes.
By running the describe command, we get more information about the cluster, including the root CA certificate, listeners and configurations:
kubectl describe Kafka -n kafka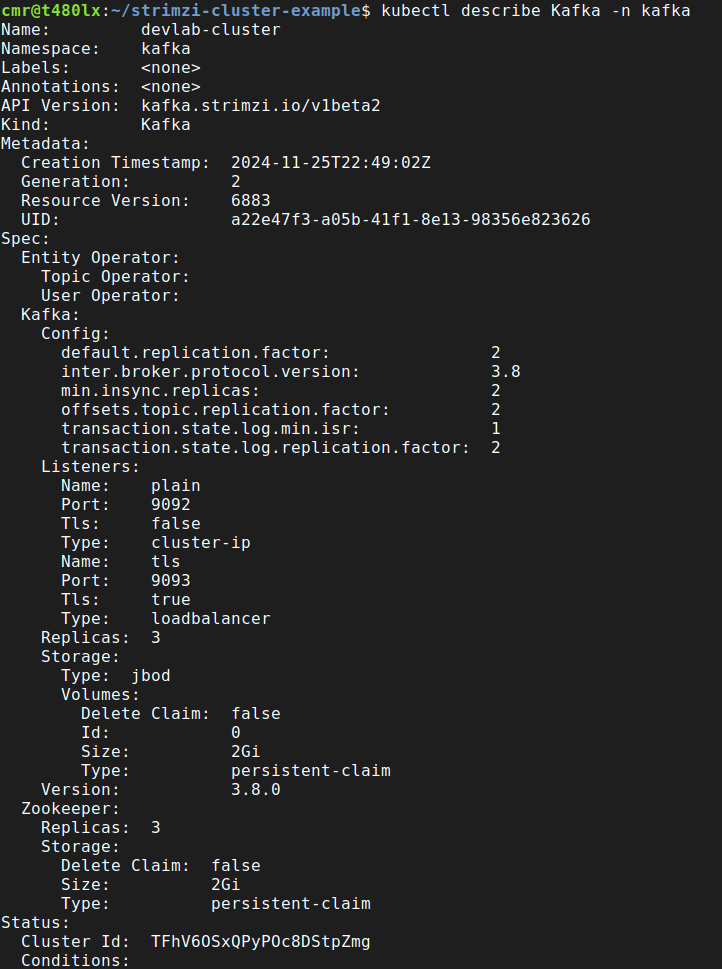
Creating a Kafka user
We can now proceed with the creation of a test user. Let’s call it “test-user” for the lack of more original name. We’ll want this used to authenticate using TLS certificates, and to have Describe, Write and Read permissions on a topic called “events” and to be allowed to be part of a consumer group prefix called “my-consumer-group-prefix”.
Here’s the YAML specification for such a user:
apiVersion: kafka.strimzi.io/v1beta2
kind: KafkaUser
metadata:
name: test-user
labels:
strimzi.io/cluster: devlab-cluster
spec:
authentication:
type: tls
authorization:
type: simple
acls:
- resource:
type: topic
name: events
patternType: literal
operations:
- All
- resource:
type: group
name: my-consumer-group-prefix
patternType: prefix
operations:
- ReadI hope the yaml file is self explanatory. Let’s apply it:
kubectl apply -f test-kafka-user.yaml -n kafka
Now the user is created we can check its status by performing a get on the “KafkaUser” type:

Wait for the user to become ready. If not, use describe instead of get, to better understand the reason.
Lastly, because this user is setup to use TLS authentication, strimzi creates a secret, with the same name as the user, containing the certificate and key:
kubectl describe secret test-user -n kafka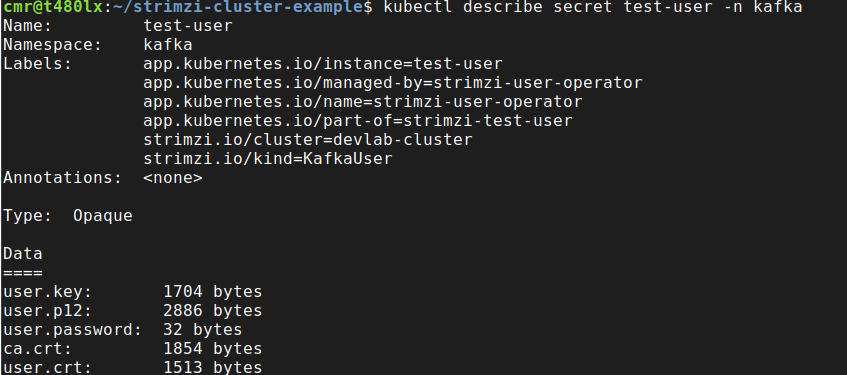
This will be useful later when we’ll need to connect to our cluster to publish or consumer messages.
Creating a Kafka Topic
The last thing we’ll do today is creating a topic. Similar to the act of creating users, topics can be created declaratively, using yaml. In the following example, we have a topic called “events” with 10 partitions and 7200000ms of retention:
apiVersion: kafka.strimzi.io/v1beta2
kind: KafkaTopic
metadata:
name: events
labels:
strimzi.io/cluster: devlab-cluster
spec:
partitions: 10
replicas: 2
config:
retention.ms: 7200000To create the topic, simply execute:
kubectl apply -f event-kafka-topic.yaml -n kafka
To ensure the topic is created in Kafka (by the entity topic operator), get the KafkaTopic object:
kubectl get kafkatopic events -n kafka
It’s also possible to describe a topic:
kubectl describe kafkatopic events -n kafka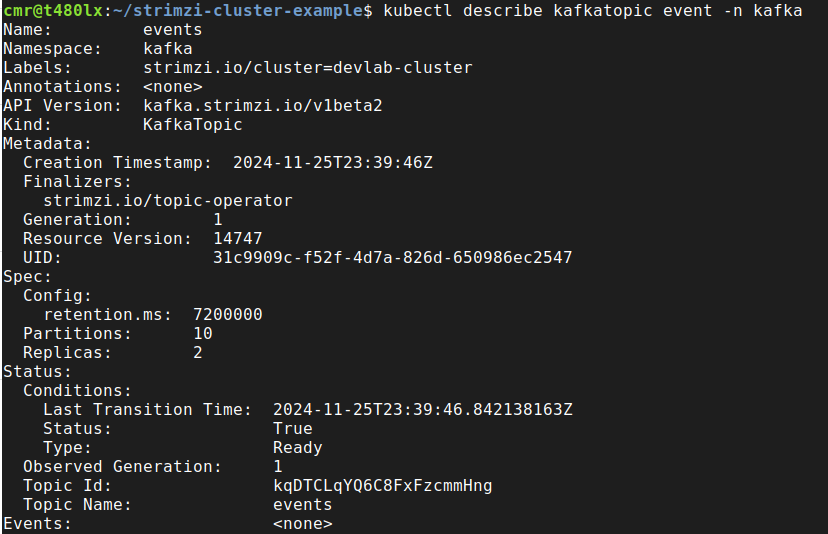
To be continued..
And that’s all for today. We’ve installed Strimzi and created a cluster, with one user and one topic.
All the yaml samples can be found in this GitHub Repo.
In the next articles of this series we’ll add cluster monitoring, we’ll see how we can connect to the cluster security, using TLS authentication and we’ll create consumers and producers using several different languages.
Stay tuned.
Sponsored links:
Kafka: The Definitive Guide: Real-Time Data and Stream Processing at Scale
Be First to Comment